
Super-Resolution Papers
Published:
In these blog post series I will be mainly focusing on my research interests and projects that I have been working on.
CDFormer: When Degradation Prediction Embraces Diffusion Model for Blind Image Super-Resolution
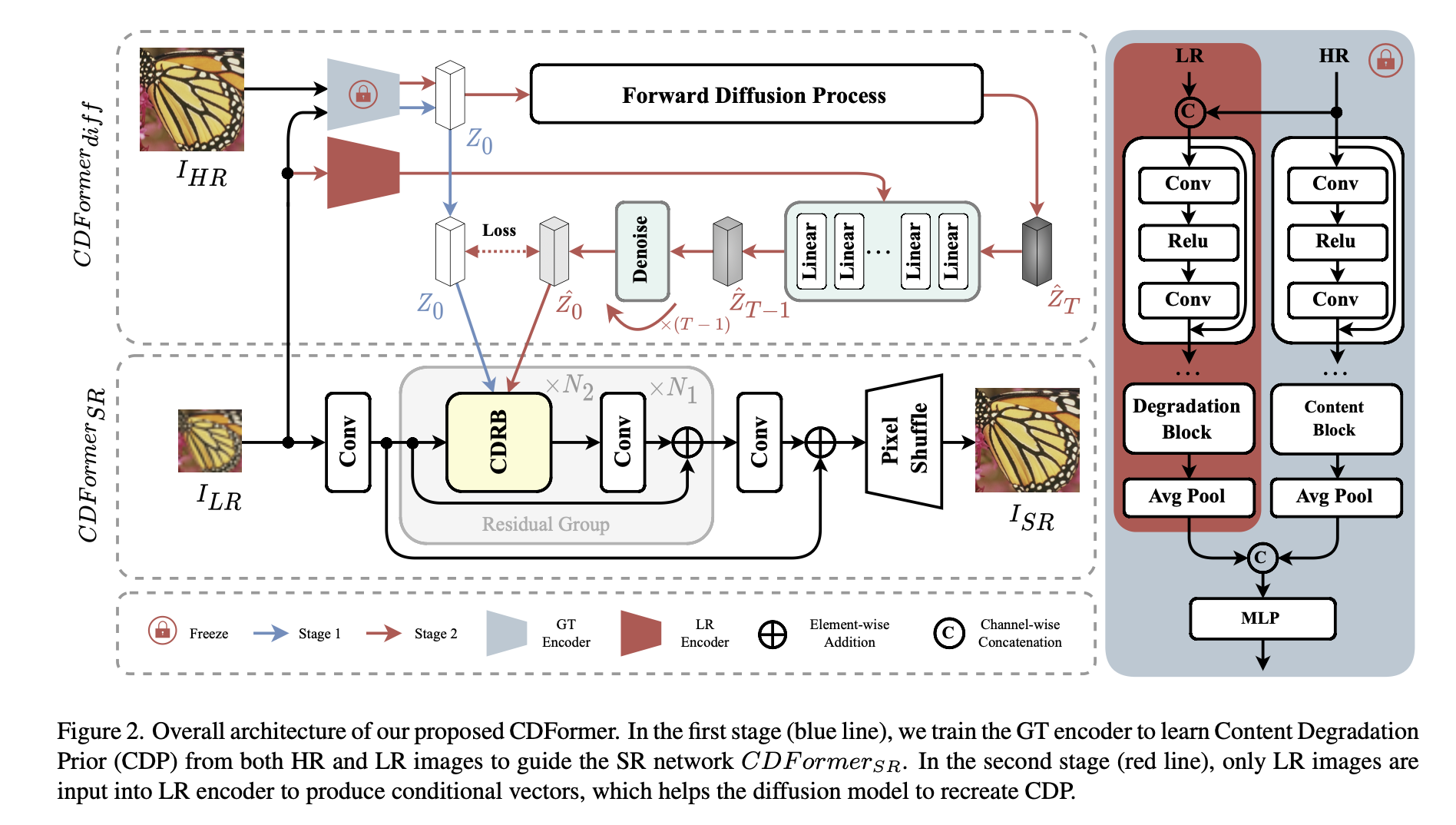
Existing methods focused on estimating kernel or degradation information, but overlooked essential content. Content-Aware Degradation-Driven Transformer (CD-Former)
Low resolution images can’t provide enough content details, so introduce a diffusion based module CDFORMER_diff to first learn Content Degradation Prior (CDP) in both LQ and HQ images then using just LQ images approximate the real distribution.
Previous Blind SR methods doing kernel prediction found ineffective with complex degradations.
Degradation prediction methods estimate degradation representation, while still in a content independent manner.
To overcome these, predict both degradation and content representations, thus reconstruct images with more harmonious textures.
Önceki BlindSR teknikleri ya kernel tahmini ya da degradation tahmini yapıyordu. Ancak bu degradation tahmini de içeriğe bağlı değildi. Bunları elimine etmek için, araştırmacıların önerisi hem degradation hem de içerik tahmini yapmak, böylece resimleri daha harmonik bir doku ile vermek.
The assumption is HQ images content HQ details, however in SR we given only LQ image, so we lack it. Adopt DM to retrace content and degradation representations from LR images.
İçerik detayı HQ imajlarda daha yoğun. Ancak SR taskında bizim buna erişimimiz yok. Bu durumda, DMi içerik ve degradation ı LR resimden öğretmek için tekrar ayarlamalıyız.
The DM in CDFormer estimate high-level info rather than recons LQ image, thus overcome the limitations of low-efficiency and excessive diversity existed in previous SR approaches.
CDFormer daki difüzyonun amacı LQ imajı reconstruct etmekten çok detaylı bilgiyi tahmin etmektir. Böylece low efficiency ve excessive diversity problemini çözüyoruz.
Moreover, transformer lacks inductive bias and CDP module gives rise to another module. adaptive Sr.
Existing methods focused on estimating kernel or degradation information, but overlooked essential content. Content-Aware Degradation-Driven Transformer (CD-Former)
Low resolution images can’t provide enough content details, so introduce a diffusion based module CDFORMER_diff to first learn Content Degradation Prior (CDP) in both LQ and HQ images then using just LQ images approximate the real distribution.
Previous Blind SR methods doing kernel prediction found ineffective with complex degradations.
Degradation prediction methods estimate degradation representation, while still in a content independent manner.
To overcome these, predict both degradation and content representations, thus reconstruct images with more harmonious textures.
Önceki BlindSR teknikleri ya kernel tahmini ya da degradation tahmini yapıyordu. Ancak bu degradation tahmini de içeriğe bağlı değildi. Bunları elimine etmek için, araştırmacıların önerisi hem degradation hem de içerik tahmini yapmak, böylece resimleri daha harmonik bir doku ile vermek.
The assumption is HQ images content HQ details, however in SR we given only LQ image, so we lack it. Adopt DM to retrace content and degradation representations from LR images.
İçerik detayı HQ imajlarda daha yoğun. Ancak SR taskında bizim buna erişimimiz yok. Bu durumda, DMi içerik ve degradation ı LR resimden öğretmek için tekrar ayarlamalıyız.
The DM in CDFormer estimate high-level info rather than recons LQ image, thus overcome the limitations of low-efficiency and excessive diversity existed in previous SR approaches.
CDFormer daki difüzyonun amacı LQ imajı reconstruct etmekten çok detaylı bilgiyi tahmin etmektir. Böylece low efficiency ve excessive diversity problemini çözüyoruz.
Moreover, transformer lacks inductive bias and CDP module gives rise to another module. adaptive Sr.
Existing methods focused on estimating kernel or degradation information, but overlooked essential content. Content-Aware Degradation-Driven Transformer (CD-Former)
Low resolution images can’t provide enough content details, so introduce a diffusion based module CDFORMER_diff to first learn Content Degradation Prior (CDP) in both LQ and HQ images then using just LQ images approximate the real distribution.
Previous Blind SR methods doing kernel prediction found ineffective with complex degradations.
Degradation prediction methods estimate degradation representation, while still in a content independent manner.
To overcome these, predict both degradation and content representations, thus reconstruct images with more harmonious textures.
Önceki BlindSR teknikleri ya kernel tahmini ya da degradation tahmini yapıyordu. Ancak bu degradation tahmini de içeriğe bağlı değildi. Bunları elimine etmek için, araştırmacıların önerisi hem degradation hem de içerik tahmini yapmak, böylece resimleri daha harmonik bir doku ile vermek.
The assumption is HQ images content HQ details, however in SR we given only LQ image, so we lack it. Adopt DM to retrace content and degradation representations from LR images.
İçerik detayı HQ imajlarda daha yoğun. Ancak SR taskında bizim buna erişimimiz yok. Bu durumda, DMi içerik ve degradation ı LR resimden öğretmek için tekrar ayarlamalıyız.
The DM in CDFormer estimate high-level info rather than recons LQ image, thus overcome the limitations of low-efficiency and excessive diversity existed in previous SR approaches.
CDFormer daki difüzyonun amacı LQ imajı reconstruct etmekten çok detaylı bilgiyi tahmin etmektir. Böylece low efficiency ve excessive diversity problemini çözüyoruz.
Moreover, transformer lacks inductive bias and CDP module gives rise to another module. adaptive Sr.
Existing methods focused on estimating kernel or degradation information, but overlooked essential content. Content-Aware Degradation-Driven Transformer (CD-Former)
Low resolution images can’t provide enough content details, so introduce a diffusion based module CDFORMER_diff to first learn Content Degradation Prior (CDP) in both LQ and HQ images then using just LQ images approximate the real distribution.
Previous Blind SR methods doing kernel prediction found ineffective with complex degradations.
Degradation prediction methods estimate degradation representation, while still in a content independent manner.
To overcome these, predict both degradation and content representations, thus reconstruct images with more harmonious textures.
Önceki BlindSR teknikleri ya kernel tahmini ya da degradation tahmini yapıyordu. Ancak bu degradation tahmini de içeriğe bağlı değildi. Bunları elimine etmek için, araştırmacıların önerisi hem degradation hem de içerik tahmini yapmak, böylece resimleri daha harmonik bir doku ile vermek.
The assumption is HQ images content HQ details, however in SR we given only LQ image, so we lack it. Adopt DM to retrace content and degradation representations from LR images.
İçerik detayı HQ imajlarda daha yoğun. Ancak SR taskında bizim buna erişimimiz yok. Bu durumda, DMi içerik ve degradation ı LR resimden öğretmek için tekrar ayarlamalıyız.
The DM in CDFormer estimate high-level info rather than recons LQ image, thus overcome the limitations of low-efficiency and excessive diversity existed in previous SR approaches.
CDFormer daki difüzyonun amacı LQ imajı reconstruct etmekten çok detaylı bilgiyi tahmin etmektir. Böylece low efficiency ve excessive diversity problemini çözüyoruz.
Moreover, transformer lacks inductive bias and CDP module gives rise to another module. adaptive Sr.
Existing methods focused on estimating kernel or degradation information, but overlooked essential content. Content-Aware Degradation-Driven Transformer (CD-Former)
Low resolution images can’t provide enough content details, so introduce a diffusion based module CDFORMER_diff to first learn Content Degradation Prior (CDP) in both LQ and HQ images then using just LQ images approximate the real distribution.
Previous Blind SR methods doing kernel prediction found ineffective with complex degradations.
Degradation prediction methods estimate degradation representation, while still in a content independent manner.
To overcome these, predict both degradation and content representations, thus reconstruct images with more harmonious textures.
Önceki BlindSR teknikleri ya kernel tahmini ya da degradation tahmini yapıyordu. Ancak bu degradation tahmini de içeriğe bağlı değildi. Bunları elimine etmek için, araştırmacıların önerisi hem degradation hem de içerik tahmini yapmak, böylece resimleri daha harmonik bir doku ile vermek.
The assumption is HQ images content HQ details, however in SR we given only LQ image, so we lack it. Adopt DM to retrace content and degradation representations from LR images.
İçerik detayı HQ imajlarda daha yoğun. Ancak SR taskında bizim buna erişimimiz yok. Bu durumda, DMi içerik ve degradation ı LR resimden öğretmek için tekrar ayarlamalıyız.
The DM in CDFormer estimate high-level info rather than recons LQ image, thus overcome the limitations of low-efficiency and excessive diversity existed in previous SR approaches.
CDFormer daki difüzyonun amacı LQ imajı reconstruct etmekten çok detaylı bilgiyi tahmin etmektir. Böylece low efficiency ve excessive diversity problemini çözüyoruz.
Moreover, transformer lacks inductive bias and CDP module gives rise to another module. adaptive Sr.